I Built a Robot Arm and Trained It to Think. Here's What I Learned.

I invest in robotics companies. I talk to founders building humanoids, manipulation systems, and autonomous machines every week. Now I've been trying to build a few robots myself.
I've been learning by ordering parts, assembling a robot arm from scratch, and training an AI policy to control it autonomously.
Here's what I did, what I learned, and why it matters.
The Build
I started with the SO-101, an open-source 6-DOF robot arm designed by The Robot Studio in collaboration with Hugging Face. It's the most popular arm in the LeRobot ecosystem right now — the same framework that a growing number of researchers and startups are building on.
The setup is a leader-follower system: two identical arms, one that I move by hand (the "leader") and one that mirrors my movements in real time (the "follower"). This isn't just a cool demo — it's the actual data collection method used by most cutting-edge robot learning systems today.
I ordered a full kit from PartaBot, sorted 12 servo motors by voltage and gear ratio, configured each motor's ID one at a time, assembled both arms from the base up, routed daisy-chain cables through each joint, and calibrated the whole system. Along the way I learned things you simply can't learn from a pitch deck: why motor horn alignment matters, why bus servos are cheap but imprecise, why a loose 3-pin cable at joint 3 kills everything downstream of it.
The Data
Once both arms were assembled and teleoperating, I added a Logitech C920x webcam and started recording demonstrations. Here's where it gets interesting.
A robotics "dataset" is fundamentally simple: it's synchronized camera images paired with motor positions at every timestep. Each frame is a snapshot that says "given what the robot sees right now, here's what the human operator did next." That's it. That's the training data.
I recorded 5 episodes of a simple pick-and-place task — grab a battery, move it to the right, put it down. Each episode was 30 seconds, with 15 seconds in between to reset the object. Total recording time: about 4 minutes.
The Training
I trained an ACT policy — Action Chunking with Transformers — which is the same architecture behind a lot of the cutting-edge imitation learning research right now. It uses a ResNet18 vision encoder to process camera images and a transformer to predict chunks of 100 future motor actions at once, making movements smooth and coherent.
52 million parameters. 100,000 training steps. Ran overnight on a MacBook M5 Pro using Apple's MPS acceleration. No cloud GPU needed.
The loss dropped from 0.070 early in training to 0.028 at the end. The network was learning. But learning what, exactly, from only 5 demonstrations?
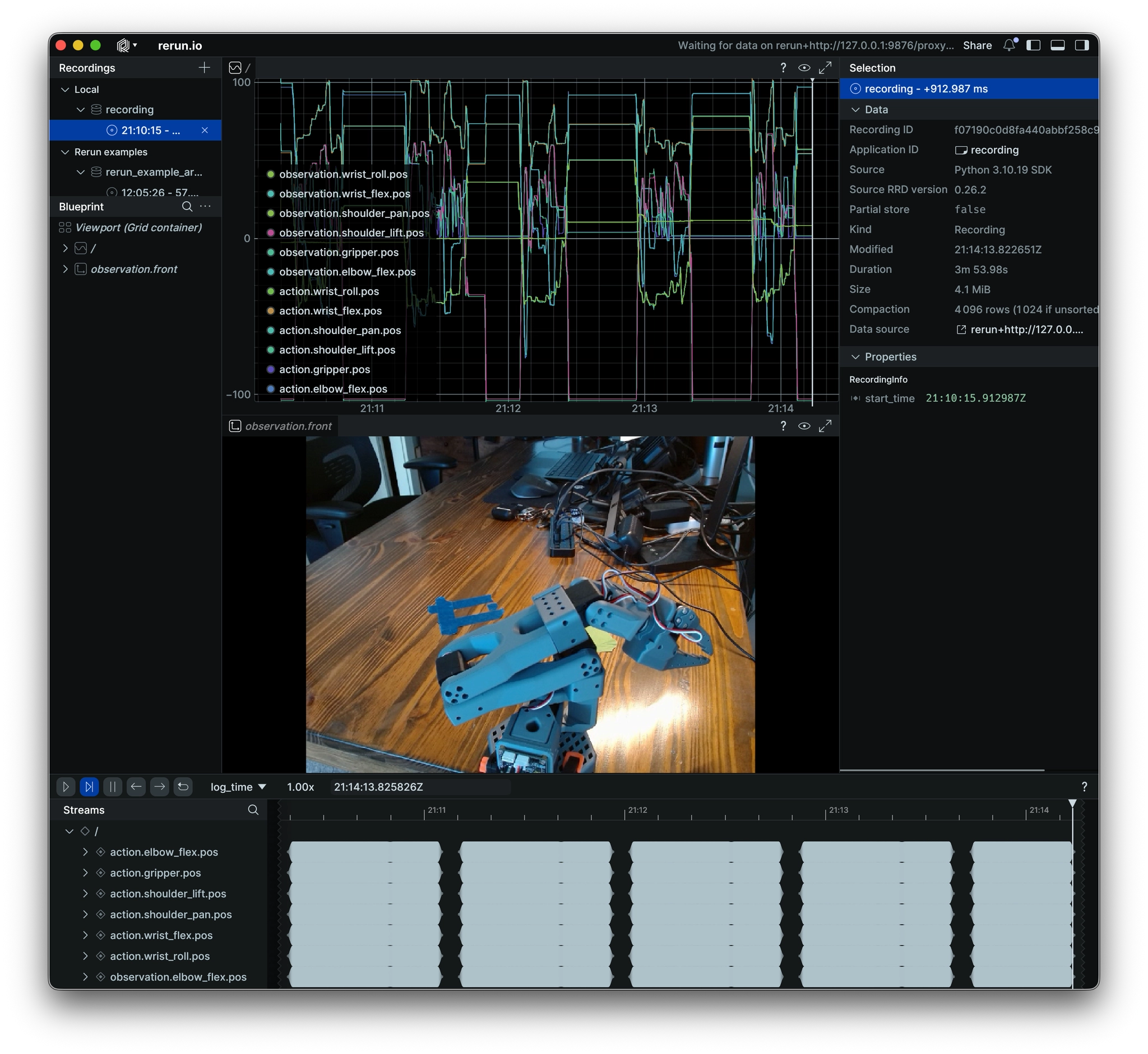
The Result
I put the battery on the table, started the policy, and watched.
The robot moved toward the battery. It knew roughly where to go and what it was trying to do. But it kept hesitating — approaching, pulling back, approaching again. It never committed to the grasp.
And honestly? That's exactly the right result. With 5 demonstrations, the policy learned intent but not execution. It saw too few examples to confidently decide when to close the gripper, what approach angle to use, or how fast to move. The uncertainty shows up as hesitation.
Why This Matters for Physical AI
This experience crystallized something I now think about constantly:
Data is the bottleneck, not the algorithm. ACT, Diffusion Policy, VLAs — these architectures all work. The question is always: how efficiently can you collect high-quality demonstration data? The jump from 5 demos (hesitation) to 50 demos (reliable grasping) to 500 demos (generalization across objects) is where the real engineering challenge lives. Companies that have solved data collection at scale have a moat. Companies still hand-teleoperating every demo do not.
The "last inch" is brutally hard. Getting an arm to move in the right general direction is easy. Getting it to close the gripper at exactly the right moment, with exactly the right force, on an object that's 2mm from where it was during training — that's where billions of dollars of R&D are being spent. I felt this viscerally when my robot hesitated. It knew where the battery was. It just couldn't commit.
Hardware matters more than people think. A loose cable, a miscalibrated joint, a motor horn mounted one tooth off — any of these can make a perfectly trained policy fail. The software gets the headlines, but the mechanical reliability and sensor quality of the physical system is often what separates a demo from a product.
Simulation-to-real is the scaling play. Recording physical demonstrations takes a lot of time. Recording 50,000 in simulation takes an afternoon. But the gap between simulated physics and real-world physics is still large enough to matter. Closing that gap — through better simulators, domain randomization, and sim-to-real transfer techniques — is one of the most important open problems in the field.
Built with: SO-ARM101 (PartaBot), Logitech C920x, MacBook Air M5 Pro, LeRobot 0.4.5, ACT policy (PyTorch MPS). All open source.