Catching Up on Fei-Fei Li: Spatial Intelligence, World Models, and the 3D Future of AI

From ImageNet to Marble — everything she's been building, saying, and arguing for
Last issue we went deep on Yann LeCun and JEPA. This time we're covering the researcher the New York Times once dubbed the "Godmother of AI" — Fei-Fei Li. The connection isn't coincidental. Both LeCun and Li are making the same fundamental argument from different angles: LLMs are not enough, the physical world is what matters, and world models are the path forward. Both stepped back from large institutional homes to build new companies. Both went from revered insiders to contrarian voices in an industry that has bet everything on scaling language.
This issue covers Li's entire arc: from immigrant physicist to ImageNet creator to Stanford AI Lab director to Google Cloud Chief AI Scientist to, now, CEO of World Labs — a company valued at billions before it had shipped a single product.
Who Is Fei-Fei Li?
Fei-Fei Li was born in Beijing in 1976 and immigrated to New Jersey as a teenager with her family, who arrived with less than $20 between them, speaking no English. She worked in restaurants and at her parents' dry-cleaning business while attending high school, eventually scoring a perfect mark in math. She received a full scholarship to Princeton — and reportedly asked two different advisors to verify the acceptance letter because she couldn't believe it. [1]
At Princeton she studied physics — a grounding in first-principles thinking that would define how she approached AI. After graduating with High Honors in 1999, she turned down Goldman Sachs to pursue a PhD at Caltech, completing her dissertation in electrical engineering in 2005. [2]
"Being a scientist is about resilience because science is exploring the unknown, just as an immigrant is exploring the unknown. In both, you are on an uncertain journey and you have to find your own North Star."
— Fei-Fei Li, Stanford HAI
She joined Stanford in 2009, became full professor in 2018, and co-founded the Stanford Institute for Human-Centered AI (HAI). She served as VP at Google and Chief Scientist of AI/ML at Google Cloud from 2017 to 2018. In 2023 she published a memoir, The Worlds I See: Curiosity, Exploration, and Discovery at the Dawn of AI. She was named Time Magazine's Person of the Year (among multiple honorees) for 2025. [3]
ImageNet: The Dataset That Changed Everything
If you want to understand what Fei-Fei Li has contributed to modern AI, you start with ImageNet. It is not an exaggeration to say that without it, the deep learning revolution would have unfolded very differently — and possibly much later.
The Problem She Was Solving
In the mid-2000s, machine learning researchers were making progress on vision, but working with tiny, narrow datasets — a few thousand images covering a handful of categories. Li recognized that algorithms were good enough; data was the bottleneck. She proposed building something unprecedented: millions of labeled images across tens of thousands of categories, mirroring the richness of the actual visual world. The idea met skepticism from some senior mentors. Building it required enormous labor, which she eventually solved by pioneering the use of Amazon Mechanical Turk for crowdsourced annotation. [4]
The final dataset: approximately 15 million images across 22,000 categories. Published in 2009. [5]
Starting in 2010, Li held an annual competition — the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). For two years, improvement was incremental. Then in 2012, Geoffrey Hinton's graduate students Alex Krizhevsky and Ilya Sutskever submitted a deep convolutional neural network called AlexNet. It cut the error rate nearly in half, shocking the field. That moment is widely considered the ignition point of the modern deep learning revolution. Li's dataset provided the fuel. [5]
"ImageNet is widely regarded as one of three key elements enabling the birth of modern AI, along with neural network algorithms and modern compute like GPUs."
— Fei-Fei Li, World Labs manifesto, 2025
The Lesson She Drew
Li has consistently credited ImageNet not just as a technical contribution but as a philosophical statement: the right data, at the right scale, structured the right way, unlocks capabilities that no amount of algorithmic cleverness alone can produce. This belief in the centrality of data quality and structure runs through everything she's done since — and is directly relevant to why she thinks AI needs to learn from rich visual data rather than flattened text. [5]
The Core Argument: Language Is Lossy Compression
Li's critique of the LLM paradigm has become one of the most-quoted in the field. Unlike LeCun, whose criticism is primarily architectural, Li's argument begins with a more primal observation about the nature of language itself.
"Language is purely a generated signal. You don't go out in nature and there are words written in the sky for you. There is a 3D world that follows the laws of physics."
— Dr. Fei-Fei Li, a16z interview, 2025 [6]
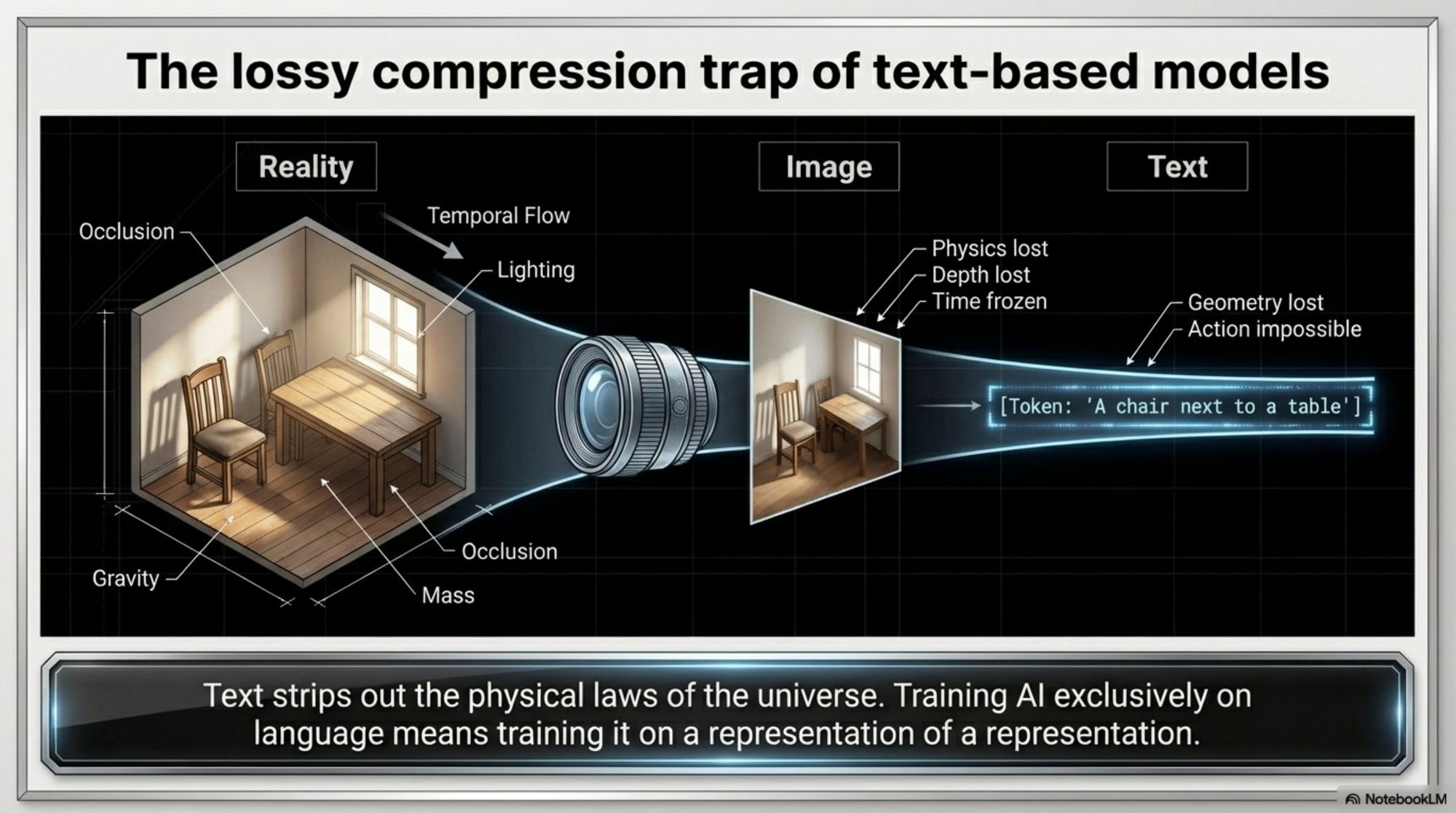
This statement — which went viral in March 2026 when a thread noted its alignment with LeCun's position — captures her central thesis. Language is a human-generated abstraction layered on top of physical reality. It is not reality. Training AI systems exclusively on language means training them on a representation of a representation: lossy compression of a world the model has never directly observed.
In her June 2025 a16z interview, she went further, describing LLMs as "lossy compression" of reality — like a JPEG that discards detail. Language captures semantic relationships but strips out physics, lighting, causality, geometry, and the temporal flow of events. World models re-inject all of that. They enable AI to reason about mass, torque, occlusion, shadows, and temporal change — concepts textual training cannot ground. [7]
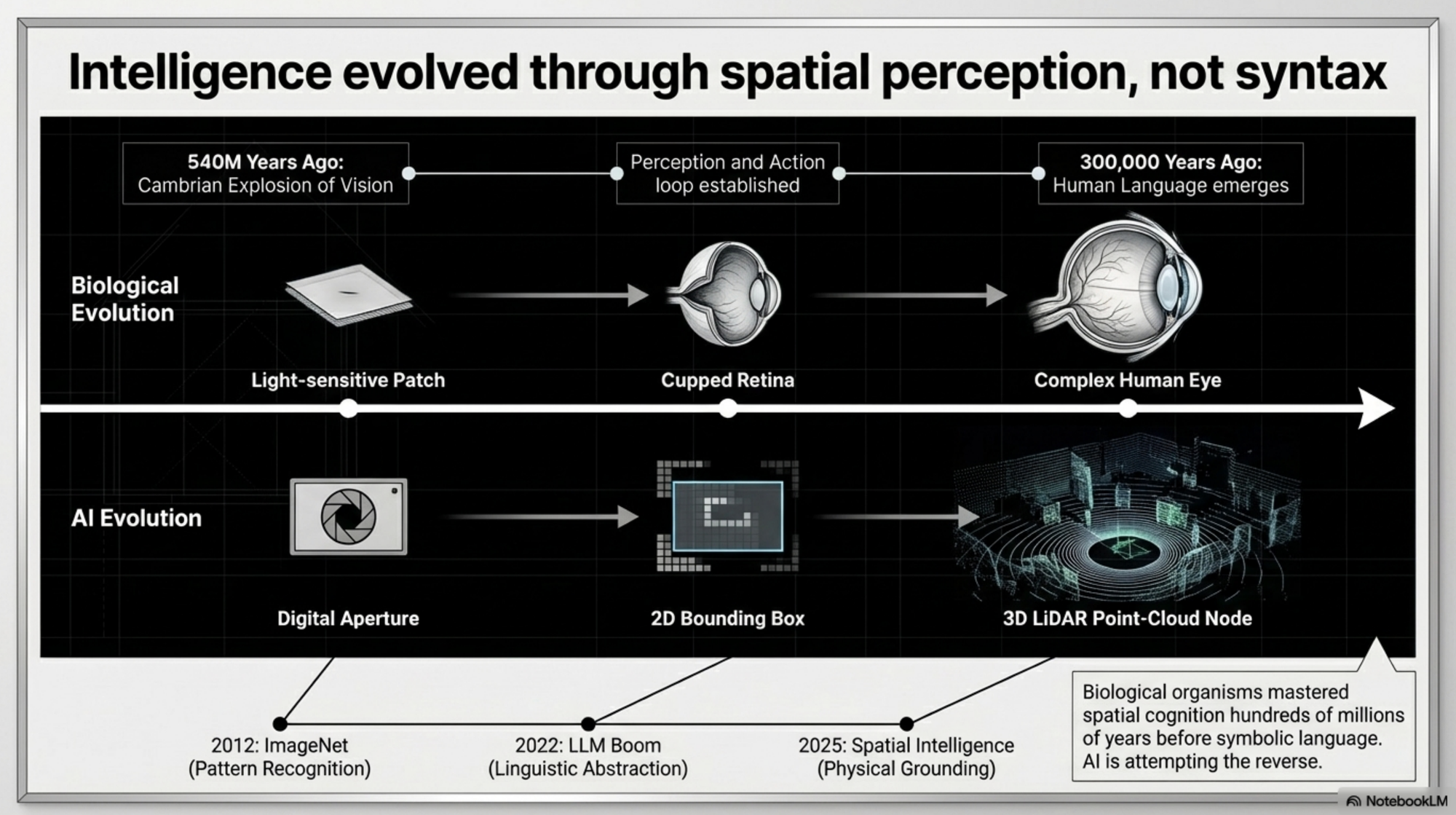
She invokes evolution to make this vivid: insects, fish, and mammals mastered spatial cognition hundreds of millions of years before symbolic language emerged. Spatial intelligence is the older and more fundamental form. Language is a late-arriving overlay — valuable but derivative. [7]
But She Is Not Anti-LLM
This is important to clarify. Li has explicitly described language as "humanity's crown jewel." She acknowledges LLMs have transformed access to knowledge. Her argument is not that language models should stop being built — it's that they are insufficient for anything involving physical interaction with the 3D world. [7]
"If AI is to be truly useful, it must understand worlds, not just words. Worlds are governed by geometry, physics, and dynamics."
— Fei-Fei Li, World Labs
What Is Spatial Intelligence?
The core concept Li has introduced and championed is spatial intelligence: an AI system's ability to perceive, model, reason about, and take actions within physical or geometric space. She describes it as "the capability that links imagination, perception and action." [8]
What it actually requires:
- Geometric understanding — the world is 3D, not flat; objects have depth, volume, occlusion, perspective
- Physical grounding — gravity pulls things down, rigid objects don't pass through each other, light follows predictable paths
- Temporal reasoning — tracking how objects change over time, anticipating trajectories, understanding causality
- Action integration — connecting perception to doing; understanding not just what a scene looks like but how an agent could interact with it [8][9]
At her NeurIPS 2024 keynote, Li framed this as a "ladder of visual intelligence." The bottom rungs — pattern recognition, image classification — are where deep learning excels. The upper rungs involve 3D structure, physical dynamics, and interactive planning. Most current AI sits near the bottom. The upper rungs are both more difficult and more important. [9]
"Tackling the problem of spatial intelligence is a fundamental and critical step towards full-scale intelligence. The world is 3D. We don't live in a flat world."
— Fei-Fei Li, IEEE Spectrum, 2024
The applications go well beyond robots: healthcare (understanding the human body as a 3D object), architecture (rapid spatial prototyping), scientific discovery (molecular and materials structures), and creative work (filmmakers, game developers, designers). [8][10]
World Labs: The Company
The Founding
World Labs was founded in early 2024. Li co-founded it with three researchers whose combined credentials represent perhaps the strongest founding team ever assembled for the spatial intelligence problem:
- Justin Johnson — computer vision researcher, PhD from Li's Stanford lab, professor at University of Michigan, known for seminal generative model work
- Ben Mildenhall — co-inventor of NeRF (Neural Radiance Fields), the breakthrough technique for 3D scene reconstruction that ignited the modern field
- Christoph Lassner — specialist in 3D human body modeling and high-fidelity rendering [11]
The Funding
The company emerged from stealth in September 2024 having already raised $230 million across two rounds from Andreessen Horowitz, NEA, Radical Ventures, NVentures (Nvidia's venture arm), and AMD Ventures. The seed round was reportedly subscribed within days. World Labs hit a $1 billion valuation in approximately twelve weeks — one of the fastest-forming unicorns in generative AI history. A further round announced February 18, 2026 brought total funding to over $1.2 billion, with new investors including Autodesk ($200M — their largest startup investment ever), AMD, NVIDIA, Emerson Collective, Fidelity, and Sea. [11][12]
The Technical Architecture
Why World Models Are Harder Than Language Models
In her November 2025 manifesto, Li laid out the technical barriers that define World Labs' research agenda:
1. A universal training objective. LLMs have next-token prediction — simple, elegant, infinitely scalable. There is no equivalent for spatial AI. Defining one is arguably the central unsolved problem. The objective must reflect the laws of geometry and physics, not just statistical co-occurrence. [13]
2. Large-scale training data. Internet video and images are abundant, but extracting 3D spatial information from 2D pixel arrays is itself a hard research problem. The 3D structure of a scene is not directly observed — it must be inferred. [13]
3. New model architectures. Standard transformers tokenize data into 1D or 2D sequences. This makes even simple spatial tasks — counting unique chairs in a video, remembering what a room looked like an hour ago — unnecessarily difficult. 3D- and 4D-aware architectures are needed. [13]
4. Consistency and persistence. A world model must maintain a coherent representation of an environment across time and viewpoints. Current AI systems tend to hallucinate inconsistencies when asked to maintain a scene from multiple angles or across time steps. [13]
RTFM: Real-Time Frame Model
One of World Labs' key technical contributions, announced in October 2025, is RTFM (Real-Time Frame Model). RTFM generates video frames interactively in real time as users navigate a scene, using posed frames as a form of spatial memory to maintain persistence and consistency — without explicit 3D reconstruction. It renders lighting, reflections, and shadows learned end-to-end from data, runs on a single H100 GPU, and was a key enabling technology for World Labs' first product. [14]
The key insight: the model doesn't rebuild the world from scratch at each frame. It remembers where it's been and reasons forward from there.
Marble: The First Product
On November 12, 2025, World Labs launched Marble — its first commercial product and the first publicly released model of its kind. Marble generates, maintains, and lets users explore persistent, consistent 3D environments from multimodal prompts: text descriptions, images, videos, panoramas, or coarse 3D layouts. Available via freemium and paid tiers. [15]
Users can describe a scene, or upload photos from a real space, and Marble will generate a navigable 3D environment. Export formats include Gaussian splats, meshes, and video. The model includes AI-native editing tools and a hybrid 3D editor — Chisel — for blocking out spatial structures before AI fills in the detail. [15]
The Launch Video Built with Marble
For Marble's launch video, the World Labs team made a bold decision: to produce the entire video using Marble itself. Every scene — a child's bedroom, a cosmic landscape, a rocky tunnel opening to a sunlit mountain — began as a prompt inside Marble, then was rendered on an LED volume stage. Weeks of environment prototyping that would have taken months with traditional 3D modeling. [16]
This wasn't clever marketing — it was a proof of concept. The team was confident enough in Marble's consistency and quality to let it generate the visual world of its own introduction.
What's Shipped Since Launch
World Labs has moved fast in the months since Marble went public. In January 2026, the company opened the World API, giving developers and robotics firms programmatic access to Marble's world generation capabilities and enabling third-party tools to embed spatial intelligence directly into their own pipelines. [12]
In February 2026, World Labs previewed Spark 2.0, the next version of its open-source Gaussian splat renderer. Spark 2.0 introduces a Level-of-Detail system, a streamable file format, and memory paging — allowing large generated worlds to render smoothly across devices including mobile hardware, a meaningful step toward broader deployment.
Most recently, in early April 2026, World Labs released Marble 1.1 and Marble 1.1 Plus. Version 1.1 is now the default model, delivering improved generation quality at the same credit cost. Marble 1.1 Plus adds automatic spatial expansion — the model dynamically extends world boundaries during generation to produce larger environments in a single pass, with variable pricing per additional "cube" of space generated. [15]
In March 2026, Fast Company named World Labs #22 on its World's 50 Most Innovative Companies list for 2026, cited specifically "for transforming text, photos, and videos into 3D worlds." Li was separately quoted: "You need a 3D environment that is interactable, that has collisions, physics, and dynamics to train and evaluate robots." — a signal of where the product roadmap is pointed.
Robotics: The Long Game
While Marble targets creative professionals today, Li has been consistent that robotics is where the stakes are highest.
"The vision of autonomous robots remains intriguing but speculative, far from the fixtures of daily life that futurists have long promised."
— Fei-Fei Li, Substack manifesto, November 2025
The reason: robots need spatial intelligence, and we haven't built it yet. An active World Labs research direction is using world models to accelerate robot training — generating physically consistent synthetic environments at scale to compress the data collection cycle that currently requires physical hardware, physical spaces, and human operators. [16]
Li uses a simple example to make the stakes tangible: a flat tire on a highway. To change it, you need a mental model of 3D space. You need to know where the jack goes under the car. You need to understand torque and the geometry of a lug nut. You need to anticipate how the car moves as it's lifted. None of this is in text. All of it is in space. [9]
The "From Words to Worlds" Manifesto (November 2025)
Timed to the Marble launch, Li published a manifesto on her Substack titled "From Words to Worlds: Spatial Intelligence is AI's Next Frontier." It is her most comprehensive public statement of the vision. [8]
The core argument:
"Building spatially intelligent AI requires something even more ambitious than LLMs: world models, a new type of generative model whose capabilities of understanding, reasoning, generation and interaction with the semantically, physically, geometrically and dynamically complex worlds — virtual or real — are far beyond the reach of today's LLMs."
— Fei-Fei Li, Substack, November 2025
Three technical priorities she identifies: a new universal training objective grounded in geometry and physics; better algorithms for extracting 3D information from 2D video; and new 3D/4D-aware architectures beyond 1D tokenization. [13]
Throughout the manifesto, Li frames World Labs' tools as superpowers for human creators, not replacements for them. This human-centered framing — rooted in her HAI work at Stanford — distinguishes her public communication from most in the field.
Li vs. the Mainstream
The Common Ground with LeCun
The alignment between Li and LeCun is striking and increasingly visible. Both argue that language models are insufficient for grounded physical intelligence, that the world is 3D and follows physics that text can't capture, that world models are the key missing ingredient, and that self-supervised learning from visual data is more promising than next-token prediction for the hardest problems. [6][8]
When a thread in March 2026 juxtaposed Li's "language is a generated signal" quote with LeCun's arguments and noted "the same vibe," it was correct. These are two of the most credentialed researchers in the field converging on the same diagnosis from different lineages. [6]
Key Differences
Approach to generation. LeCun's JEPA is explicitly non-generative — it predicts in abstract representation space and deliberately avoids pixel reconstruction. Li's World Labs builds generative world models that produce photorealistic 3D environments. Complementary but technically distinct.
Tone. LeCun is combative — he calls LLMs a "dead end" and tells researchers to avoid them. Li is more measured — she calls language "humanity's crown jewel" and emphasizes what is missing rather than what is broken.
Commercial timing. Marble is already live with freemium and paid tiers. LeCun's AMI Labs is more purely research-first, with no commercial product yet.
Primary near-term use case. LeCun's V-JEPA 2 is robotics-forward. Marble currently targets creative professionals, with robotics as a future application. [8][9][15]
Policy, HAI, and the Broader Mission
What makes Li's position genuinely unique is that she is not only a foundational researcher and a startup CEO — she is also one of the most prominent voices in AI governance.
She co-founded the Stanford Institute for Human-Centered AI (HAI) with former Stanford Provost John Etchemendy. She has testified before the U.S. Senate and Congress on AI policy, served as a special advisor to the UN Secretary General, and was a member of both the California Future of Work Commission and the National AI Research Resource Task Force. [3]
At the AI Action Summit in Paris in February 2025, she made what is perhaps her most important policy argument: AI governance should be based on science, not science fiction. She urged policymakers to adopt a more evidence-based approach to assessing AI capabilities and limitations, arguing that much of the public discourse around AI risk is driven by narrative rather than evidence. [3]
On AGI: Li has been remarkably consistent in refusing to treat it as a meaningful technical target. She prefers concrete, measurable research objectives — spatial understanding, 3D reasoning, robotic planning. A 2024 TechCrunch headline captured this perfectly: "Even the 'Godmother of AI' Has No Idea What AGI Is."
She also co-founded AI4ALL in 2017 — a nonprofit that offers AI courses to high school students, particularly young women and students of color. Her argument: who builds AI determines what AI does. [3]
The Bottom Line
Zoom out from Marble and RTFM, and a coherent long-term vision comes into focus. Li is arguing, through both research and company building, that the next phase of AI must be grounded in physics, interactive and persistent, built for humans — and governed scientifically.
"Spatial intelligence will transform how we create and interact with real and virtual worlds — revolutionizing storytelling, creativity, robotics, scientific discovery, and beyond. This is AI's next frontier."
— Fei-Fei Li, TIME, December 2025
Li's arc — from a teenage immigrant working in a dry-cleaning store to the creator of the dataset that sparked the deep learning revolution to the CEO of a billion-dollar spatial AI company — is one of the most remarkable in the history of technology. More than her individual achievements, what stands out is the consistency of her vision:
Data matters. The physical world matters. Human intelligence is fundamentally spatial. Any AI system that ignores these facts will hit a ceiling.
She has been saying this, in one form or another, since she started building ImageNet in a grad school lab with a shoestring budget and some Amazon Mechanical Turk accounts. The field is only now catching up with her.
Notebook LM Explainers:
Short Video:
Deep Dive Podcast:
Slides:

References
[1] Stanford HAI. "Fei-Fei Li: A Candid Look at a Young Immigrant's Rise to AI Trailblazer."
[2] Stanford University School of Engineering. Fei-Fei Li Faculty Profile.
[3] Wikipedia. "Fei-Fei Li."
[4] Britannica. "Fei-Fei Li."
[5] Li, Fei-Fei, et al. "ImageNet: A Large-Scale Hierarchical Image Database." CVPR, 2009
[6] Rohan Paul (@rohanpaul_ai). Thread on Fei-Fei Li a16z quote. Twitter/X, March 5, 2026 (Twitter/X links are unstable — search "@rohanpaul_ai Fei-Fei Li spatial" to locate)
[7] NYQuiste. "World Labs Raises Stakes in Spatial Intelligence: Fei-Fei Li Tells a16z 'World Models, Not LLMs, Are the Next Frontier.'" June 2025
[8] Li, Fei-Fei. "From Words to Worlds: Spatial Intelligence is AI's Next Frontier." Substack, November 10, 2025
[9] IEEE Spectrum. "AI Pioneer Fei-Fei Li Has a Vision for Computer Vision." December 2024
[10] TIME. "Spatial Intelligence Is AI's Next Frontier." By Fei-Fei Li. December 11, 2025
[11] Andreessen Horowitz. "What's In a World? Investing in World Labs." September 2024
[12] TechCrunch. "World Labs Lands $1B, With $200M from Autodesk, to Bring World Models into 3D Workflows." February 18, 2026
[13] Radical Ventures. "Building Spatially Intelligent AI." November 17, 2025
[14] Contrary Research. "World Labs Business Breakdown & Founding Story." Including RTFM details.
[15] TechCrunch. "Fei-Fei Li's World Labs Speeds Up the World Model Race with Marble." November 12, 2025
[16] World Labs. "Bringing Marble to Life." November 12, 2025
[17] Fast Company. "Fei-Fei Li's World Labs Unveils Its World-Generating AI Model." November 13, 2025
[18] Li, Fei-Fei. The Worlds I See: Curiosity, Exploration, and Discovery at the Dawn of AI. Flatiron Books, 2023
[19] Fast Company. "World Labs, #22: Most Innovative Companies 2026." March 24, 2026
[20] Radiance Fields. "World Labs Releases Marble 1.1 and Marble 1.1 Plus." April 2026